Evolutionary Algos, Reinforcement Learning, and Pacman
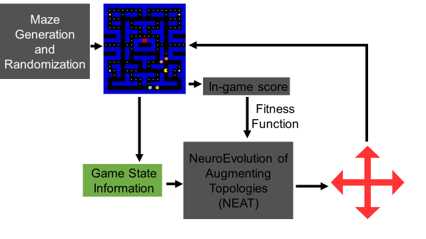
In the APS360 course, my team was given a choice of any AI-based project to work on. We developed an AI model to play PAC-MAN using an evolutionary algorithm called NeuroEvolution of Augmenting Topologies (NEAT). This AI navigates the maze, collects pellets, and avoids ghosts to maximize its score. NEAT is particularly suited for this task as it evolves both the architecture and weights of the neural network over time, allowing the model to adapt dynamically to the game environment.
We implemented the project using a Python-based PAC-MAN clone called PY-MAN. The model trained directly through gameplay, with fitness determined by in-game scores, as well as custom heuristics. We also made sure the maps were generated dynamically to avoid the AI overfitting to/memorizing the task.

Map generation algorithm Source
We experimented with various input models, eventually optimizing the “OneHit” model. This model leverages Breadth-First Search (BFS) distances and line-of-sight data to make real-time decisions. It processes 20 inputs, such as distances to the nearest pellet, power pellet, ghosts, and other game elements, to decide PAC-MAN’s movement direction.
Block diagram of inputs and outputs
We made the decision to use BFS after realizing that AI could not calculate distances as well as traditional algorithms, but it could use that information to make smart, high level decisions.

Some gameplay from the “OneHit” model
After completing the NEAT-based project, I wanted to explore if reinforcement learning (RL) could perform better. Despite occasionally getting extremely high scores, the models produced by NEAT could sometimes be inconsistent. On my own, I ran some experiments with A2C, but soon realized that I needed more compute power to test various state space inputs effectively. The RL model found creative ways to break the game, and each training round required days, so I could not effectively tune hyperparameters without having more dedicated computer power (even if I ran it without rendering the game, which made training much faster). Additionally, I concluded that in a deterministic environment like PAC-MAN, RL might not be the most ideal approach, as it doesn’t leverage the strengths of non-deterministic environments where uncertainty and exploration are key.
Key Learnings:
- AI in Real-Time Strategy:
- Developed an AI using NEAT that adapts to dynamic gameplay conditions by evolving its strategy in real-time.
- Model Optimization:
- Enhanced AI performance by experimenting with different input representations, including rotational and translational invariance, and using BFS for efficient pathfinding.
- Exploration with Reinforcement Learning:
- Attempted to improve performance with RL, but found it less suitable for the deterministic nature of PAC-MAN, highlighting the importance of environment characteristics in algorithm selection.
For more details, check out the projects on Github: NEAT, Reinforcement Learning.